2025.10.24
如何实现固定缓存大小
HashMap,ConcurrentHashMap可以作为缓存使用 但HashMap本身不是线程安全的 但是作为基础的Java集合 不管是HashMap还是ConcurrentHashMap本身不具备自动的数据淘汰机制,这样可能会导致OOM(内存溢出)
淘汰机制:FIFO(先进缓存先被淘汰),LRU(最近最少使用),LFU(最近最少频率使用),从左往右命中率越来越高,成本也越来越高
对于加了淘汰机制的HashMap仍然存在几个问题:锁竞争激烈,不支持过期时间,不知此自动刷新,于是出现了Guava Caffeine…
引导类:是指在框架或应用程序中负责启动和初始化的核心类。Springboot中引导类即Application为后缀的类 对于该项目 配置了一个缓存引导类CacheBS方便用户使用
|
|
实现过期时间expire
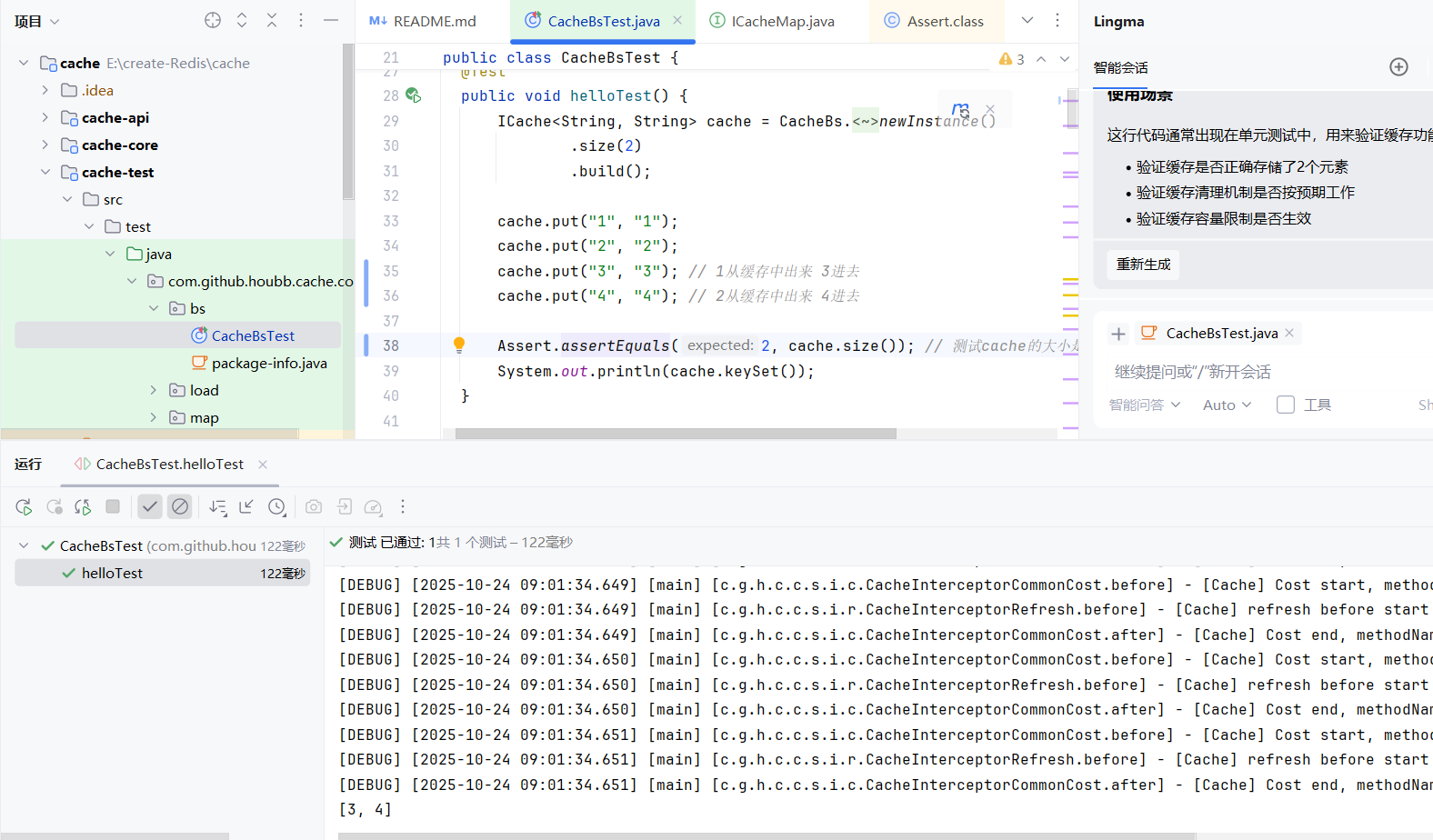
Redis中的expire可以用于验证码失效,登录token失效等业务场景… 设计一个cacheExpire接口 可以计算多久之后过期
过期的实现原理:可以通过一个定时任务比如一秒钟一次轮询,一次清理10个数据,直到将过期的信息清空。可以将过期数据存入到map中 key对应过期的数据 value对应过期时间。在这里定义了一个单线程 用来执行清空任务,清空任务执行的过程即遍历map中的key 判断value是否过期,为了避免单词执行时间太久 所以设置一个单次清空最大数量限制。
定时任务优化:可以通过排序Map快速判断哪些过期数据需要清理,即让过期时间作为key,让相同过期时间的数据放入列表中作为value。
由于我们采用了定时轮询的方式 所以有时候数据可能清理不及时 当访问数据的时候可能访问到脏数据。因此引入了惰性删除,当用到某个数据的时候 才对数据进行删除判断操作。
具体实现:在用到某些数据之前 先对数据进行刷新操作
|
|
expire过期如何随机获取key
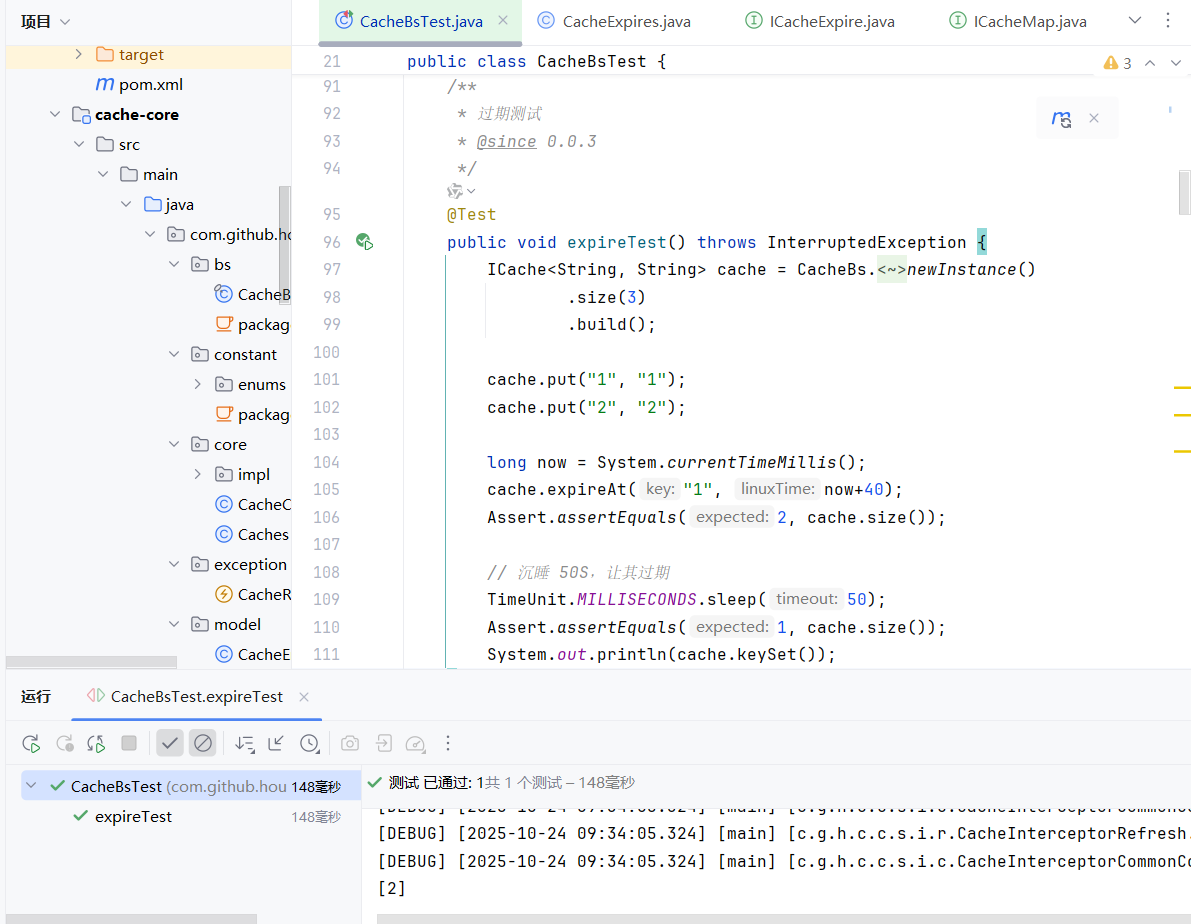
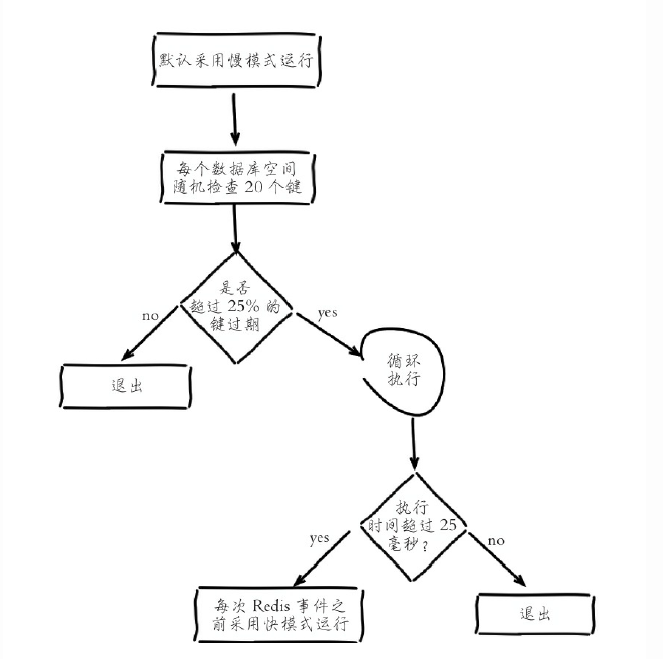
之前实现的过期很简单 用hashMap存储过期数据,然后轮询处理,执行定时清理任务 redis实现的定时清理任务并不是时时刻刻都在执行的,定时任务中删除过期键逻辑采用了自适应算法,根据键的过期比例、使用快慢两种速率模式回收键,如图所示,先随机抽取key 如果有四分之一以上的key过期则执行 否则不执行
实现内存数据重启不丢失
由于我们的数据是放在内存中的 如何保证重启之后数据还在?(Redis持久化)
Redis的持久化机制包括三种:RDB(快照),AOF(只追加文件),混合策略.
这里我们先实现RDB快照模式,我们可以在缓存启动的时候,可以通过指定初始化加载的信息,从而实现数据持久化。现在我们需要知道如何将缓存中的内容持久化到文件或数据库中?,知道这些信息,就可以在重启之后加载这些信息,来保证数据不丢失了。对于导出的文件来说还有很多细节,比如文件的压缩,CRC校验…

|
|
AOF模式:RDB模式将缓存内容全部持久化比较耗时, AOF模式针对修改内容的指令,将指令顺序添加到文件中,因此AOF的实时性更好,顺序写避免了IO的随机写问题。

添加监听器
-
删除监听器:我们之前已经实现expire 是对用户透明的(用户感知不到),并且当内存满了的时候,Redis会进行内存淘汰(evict 淘汰),这对用户来说也是透明的 如果用户想获取到这些信息,可以通过添加监听器实现。即在删除的位置调用监听器即可。
-
慢操作监听器:redis 中会存储慢操作的相关日志信息(参数包括:耗时阈值,最多存储多少条慢日志记录) 所有我们可以对于所有的操作记录操作耗时 如果耗时超过用户设置的阈值 调用慢操作监听器
-
自定义监听器…

2025.10.26
LRU 缓存淘汰
LRU最近最少使用 是一种比较常见的淘汰算法 如果数据最近被访问过 就认为被访问的概率更高
局部性准则:时间局部性(最近被访问过,再次访问的肯可能性很高)和空间局部性(访问到某个磁盘信息,接下来可能访问局部的存储空间)缓存中用到的LRU即遵循了时间局部性准则
实现:利用链表 新数据插入到链表头部 缓存命中,将命中数据移到链表头部 如果链表满了丢弃链表尾部数据。 代码实现起来需要用到:链表插入,如何判断缓存命中(HashMap),链表删除等知识
|
|
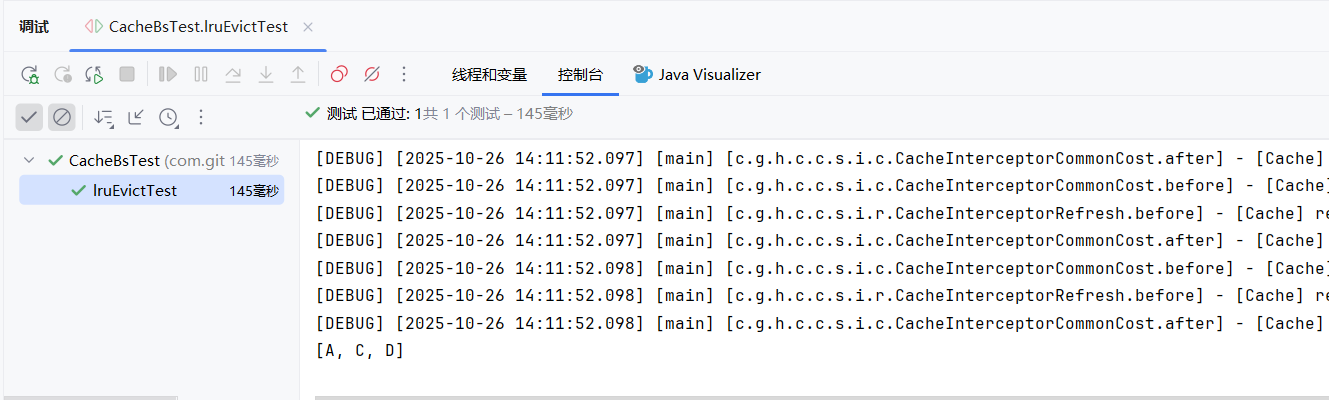
如果是FIFO 结果应该是[B,C,D] 由于是LRU A最近被访问过 所以淘汰的是B 结果是[A,C,D]
LRU 缓存淘汰优化
优化思路:1.用一个数组存储时间戳 为每个数据添加一个时间戳属性 每次访问数据时,更新该数据的时间戳 当数据空间满的时候 扫描时间戳最小的数据 但是需要用空间存储时间戳 并且淘汰数据的时候需要扫描整个数组
2.之前的简单实现是基于链表的 由于链表的性质(链表中插入和删除某个已知元素的时间复杂度是O(1),但是插入和删除之前需要遍历链表找到元素时间复杂度是O(N))因此可以用双向链表优化一下淘汰末尾数据的操作
3.双向链表查找某个元素依然需要遍历链表 时间复杂度是O(n) 可以基于双向链表和哈希表 将哈希表中的数据和链表中的节点形成映射 插入和删除操作的时间复杂度下降为O(1) 但是引入哈希表会造成空间开销
LinkedHashMap是一种list和HashMap结合的数据结构 但是LinkedHashMap不会淘汰数据 可以重写removeEldestEntry方法实现淘汰数据。
LRU 缓存淘汰算法如何避免缓存污染
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
1.LRU-K算法:LRU是将最近使用一次的数据放入缓存 LRU-K是通过维护一个队列,用于记录缓存数据被访问的历史 当某个数据的访问次数达到K时 将数据放入缓存 数据淘汰的时候淘汰第K次访问时间距当前时间最大的数据 数据第一次被访问时,加入到历史访问列表,如果数据在访问历史列表中没有达到K次访问,则按照一定的规则(FIFO,LRU)淘汰;
当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列中删除,将数据移到缓存队列中,并缓存数据,缓存队列重新按照时间排序;
缓存数据队列中被再次访问后,重新排序,需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即“淘汰倒数K次访问离现在最久的数据”。
2.2Q算法 将LRU-2中的历史访问列表改为FIFO缓存队列 因此2Q算法中有两个缓存队列:FIFO队列和 LRU队列
3.MQ算法 根据数据的访问频率将数据分为多个队列 不同的队列有不同的访问优先级 优先缓存访问次数最多的数据。
最近最不常用(LFU)淘汰算法
LFU将频率上最不常访问的数据淘汰 需要额外存储每个数据的访问次数
如果用HashMap将key放数据,value放访问次数的话 新增和查询的时间复杂度都是O(1),但是删除就需要遍历HashMap时间复杂度为O(n)。在此基础上,用小顶堆+HashMap 插入和删除的操作是O(logn)。如果在淘汰数据的时候想要实现O(1)的时间复杂度,可以利用双Hashmap,HashMap中存放 key 和节点之间的映射关系,节点中的value保存对应的访问次数信息 相同的访问次数同freqMap进行关联 可以通过频率获取响应的链表
基于上面两种淘汰策略可以看到LFU是基于访问频次的模式,而LRU是基于访问时间的模式。
Clock 页面置换算法
操作系统使用的内存管理即Clock页面置换算法,该算法通过链接指针将内存中的所有页面组织成一个循环队列,并为每个页面设置一个访问位。当页面被访问时,其访问位设置为1。当需要淘汰页面以释放空间时,算法会扫描循环队列,选择访问位为0的页面进行置换。如果所有页面的访问位均为1,则将它们置为0并进行第二轮扫描。
实现:循环链表 + map 改进后的Clock页面置换算法:除了访问位,添加一个修改位 考虑了页面是否被修改过 优先淘汰未被修改过的页面
分布式锁
Jdk中提供了加锁方式:synchronized加锁,乐观锁,读写锁,可重入锁…在单机系统中为多线程情况下保证线程安全。在分布式系统中,上面的锁不再适用,因此为了解决分布式系统中的并发问题 需要引入分布式锁。 参考:分布式锁原理
分布式锁:是一种跨节点,跨服务的互斥机制,一个可靠的分布式锁需要满足:互斥性,安全性,防死锁,可用性,容错性。 实现的核心原理:通过SET命令实现互斥 即用一个redis键作为锁的标识 当客户端对某个共享资源获取锁时,需要判断该资源是否已上锁 没上锁的时候才可以设置锁键获取锁,释放锁的时候删除锁键即可(在释放锁的时候可以通过Lua脚本实现操作的原子性)。 SET命令的两个参数:NX(not exist) 用于获取锁 PX设置锁键的过期时间
获取锁的命令比如:SET lock:stock client1 NX PX 30000
HashMap源码
HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的。HashMap实例有两个影响其性能的参数: 初始容量(16)和负载因子(默认0.75),阈值可以通过threshold = length * Load factor计算。HashMap非线程安全
参考:hashmap源码分析
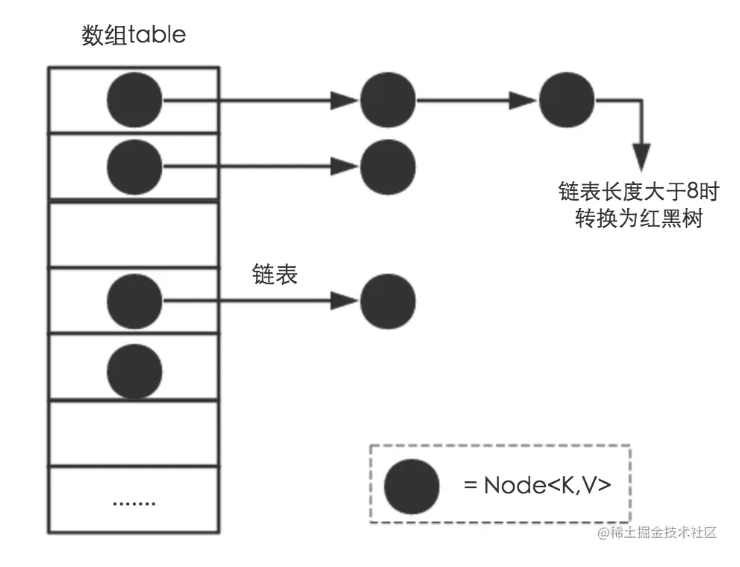
HashMap类中有一个非常重要的字段,就是 Node[] table,即哈希桶数组。
哈希桶是一种通过链地址法(开散列法)解决哈希冲突的结构。它将具有相同散列地址的元素存储在一个链表中,每个链表被称为一个哈希桶.
HashMap是使用哈希表存储的 哈希表为了解决哈希冲突 可以采用开放地址法和链地址法,HashMap采用了链地址法。为了控制hash冲突发生的概率且让哈希桶数组的占用空间少,于是需要一个好的Hash算法和扩容机制。
扩容机制:Node[] table(哈希桶数组),初始化长度为16,负载因子为0.75,阈值为初始化长度 * 负载因子。当数量超过阈值时需要扩容,扩容之后HashMap容量是之前的2倍。在HashMap中,哈希桶数组table的长度length大小必须为2的n次方(一定是合数),这种设计主要是为了在取模和扩容时做优化,同时为了减少冲突,HashMap定位哈希桶索引位置时,也加入了高位参与运算的过程。在JDK1.8中,引入了红黑树,当链表长度过大(超过8),链表转化为红黑树。因为红黑树的查找时间复杂度为O(logn) 链表查找的时间复杂度为O(n).Java中的数组不会自动扩容,实际上是通过一个新的数组代替原有的数组,通过resize方法实现。在多线程使用场景中,应该尽量避免使用线程不安全的HashMap,而使用线程安全的ConcurrentHashMap。