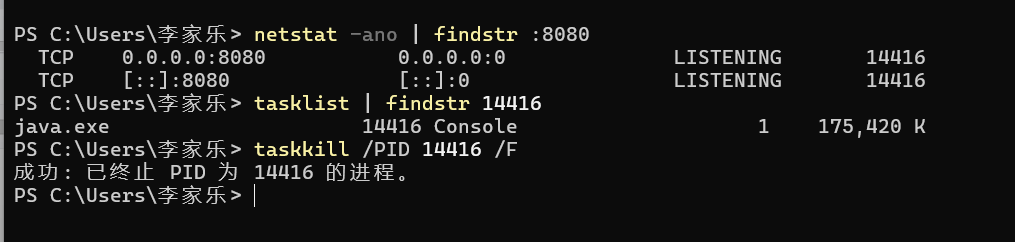
对于某些需要隐私保护的文件或者内容不太适合用在线翻译软件,因此可以在自己电脑上实现一个翻译器
首先看一下百度翻译的页面包括好多功能,文本翻译,图片翻译… 今天先简单实现一下文本翻译
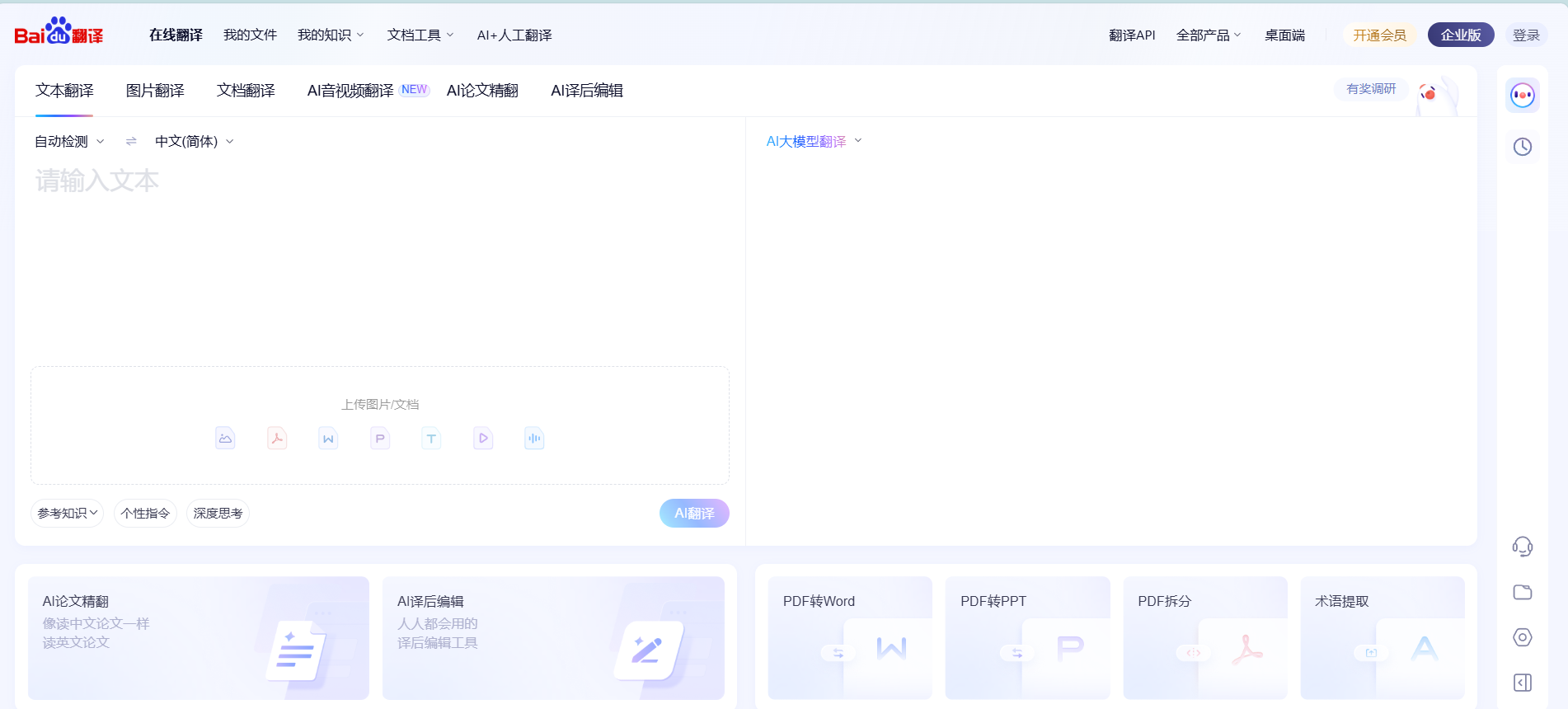
对于一个翻译系统其实很简单 只要前端点击翻译按钮 后端能返回响应结果即可 关键在于如何返回正确的结果 这里我先创建了一个翻译器V1 用于测试前后端联动是否可以打通
如果想要识别语言并且返回正确结果 可以有两种方法 一种是调用厂家的API 一种是调用大模型,提供prompt让大模型当你的翻译官即可
可以在百度翻译开放平台获取API和密钥
可以在TranslationService中调用API实现调用接口进行翻译
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
package com.example.translation.service;
import org.springframework.stereotype.Service;
import java.net.URLEncoder;
import java.nio.charset.StandardCharsets;
import java.security.MessageDigest;
import java.util.UUID;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
@Service
public class TranslationService {
// 替换为你自己的百度翻译 AppID 和密钥
private static final String APP_ID = "你的AppID";
private static final String SECURITY_KEY = "你的密钥";
public String translate(String text, String targetLang) {
try {
String from = "auto";
String to = getBaiduLangCode(targetLang);
String salt = UUID.randomUUID().toString();
String sign = md5(APP_ID + text + salt + SECURITY_KEY);
String encodedText = URLEncoder.encode(text, StandardCharsets.UTF_8);
String urlStr = String.format(
"https://fanyi-api.baidu.com/api/trans/vip/translate?q=%s&from=%s&to=%s&appid=%s&salt=%s&sign=%s",
encodedText, from, to, APP_ID, salt, sign);
URL url = new URL(urlStr);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
conn.connect();
BufferedReader reader = new BufferedReader(
new InputStreamReader(conn.getInputStream(), StandardCharsets.UTF_8));
StringBuilder result = new StringBuilder();
String line;
while ((line = reader.readLine()) != null) {
result.append(line);
}
reader.close();
conn.disconnect();
// 简单解析返回内容
String res = result.toString();
int start = res.indexOf("\"dst\":\"");
if (start > 0) {
int end = res.indexOf("\"}", start);
return res.substring(start + 7, end).replace("\\n", "\n").replace("\\u", "u");
}
return "翻译失败:" + res;
} catch (Exception e) {
e.printStackTrace();
return "翻译错误:" + e.getMessage();
}
}
private String getBaiduLangCode(String target) {
return switch (target.toLowerCase()) {
case "english" -> "en";
case "japanese" -> "jp";
case "korean" -> "kor";
case "french" -> "fra";
case "german" -> "de";
default -> "en";
};
}
private String md5(String input) throws Exception {
MessageDigest md = MessageDigest.getInstance("MD5");
byte[] array = md.digest(input.getBytes(StandardCharsets.UTF_8));
StringBuilder sb = new StringBuilder();
for (byte b : array) {
sb.append(String.format("%02x", b & 0xff));
}
return sb.toString();
}
}
|
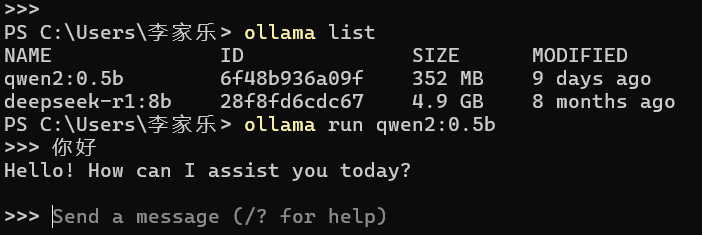
由于我电脑上面下载的有Ollama 所以我选择调用本地大模型的接口服务 实现翻译功能 不知道的同学可以下载一下ollama 然后下载一个模型 建议qwen:0.5b 即可 其他模型占用内存太大 输入ollama list 看一下本地已经下载了哪些模型
打开Windows终端 输入命令 ollama run qwen2:0.5b
给模型设置提示词然后让后端服务调用本地大模型即可实现翻译功能
1
2
3
|
Map<String, Object> body = new HashMap<>();
body.put("model", "qwen2:0.5b");
body.put("prompt", "请将以下文本翻译成英文:" + text);
|
接下来启动服务 看一下效果
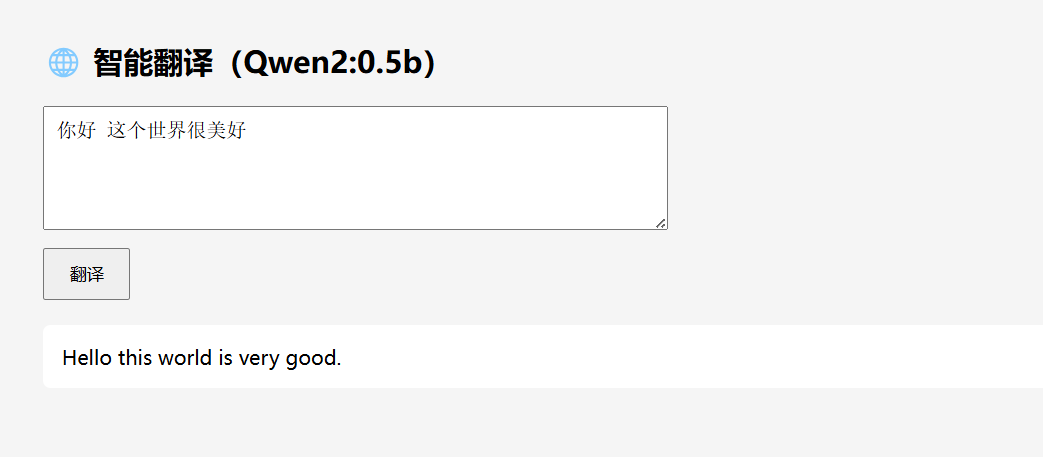
遇到的问题:在运行的时候 我的8080端口号被占用了 可以换一个端口号 也可以将启动的服务关闭 这里我选择关闭现有服务 然后重新启动 监听8080端口