1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
from flask import Flask, request, jsonify
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
import jieba
import joblib
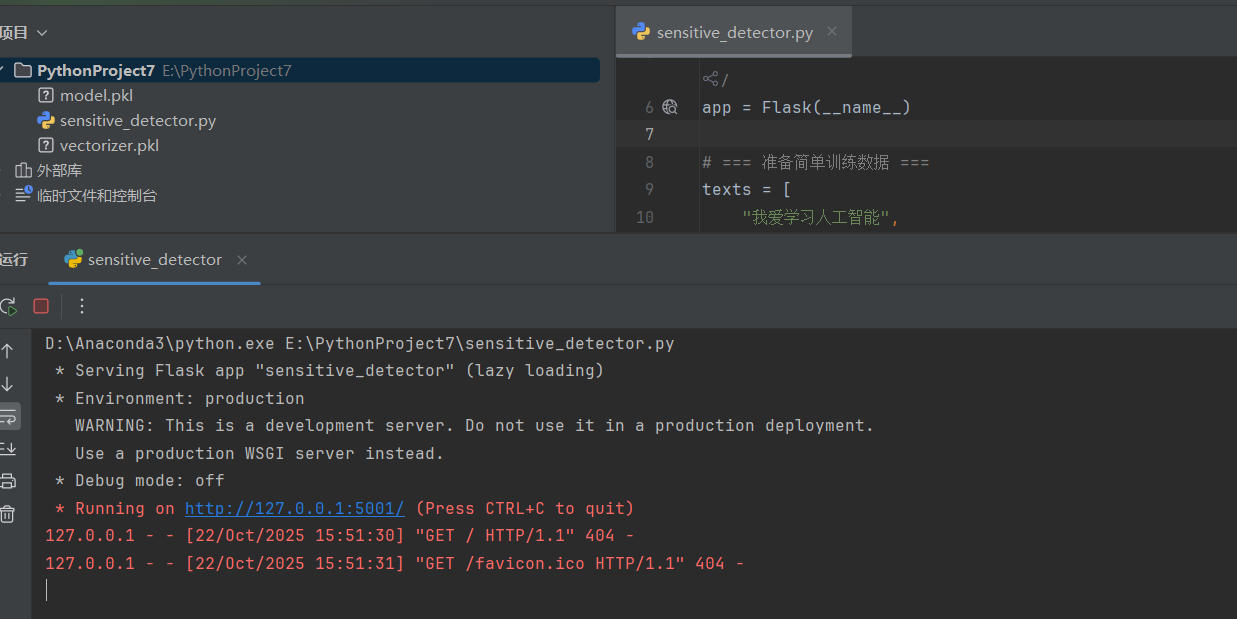
app = Flask ( __name__ )
# === 1. 准备数据 ===
texts = [
# 正常内容
"我爱学习人工智能",
"今天真开心",
"你好,朋友",
"祝你生活愉快",
"我喜欢听音乐",
"看电影真有趣",
"一起打游戏吧",
"美丽的风景让人心情愉快",
# 敏感内容
"买枪支弹药请加我",
"出售身份证",
"这是黄色网站链接",
"成人内容免费看",
"黄色小说推荐",
"如何制作炸弹",
"赌博网站登录入口",
"免费看黄片"
]
labels = [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1] # 0=正常,1=敏感
# === 2. 中文分词函数 ===
def chinese_tokenizer(text):
return jieba.lcut ( text )
# === 3. 向量化 + 训练模型 ===
vectorizer = TfidfVectorizer ( tokenizer=chinese_tokenizer )
X = vectorizer.fit_transform ( texts )
model = MultinomialNB ()
model.fit ( X, labels )
# === 4. 保存模型(方便部署) ===
joblib.dump ( vectorizer, 'vectorizer.pkl' )
joblib.dump ( model, 'model.pkl' )
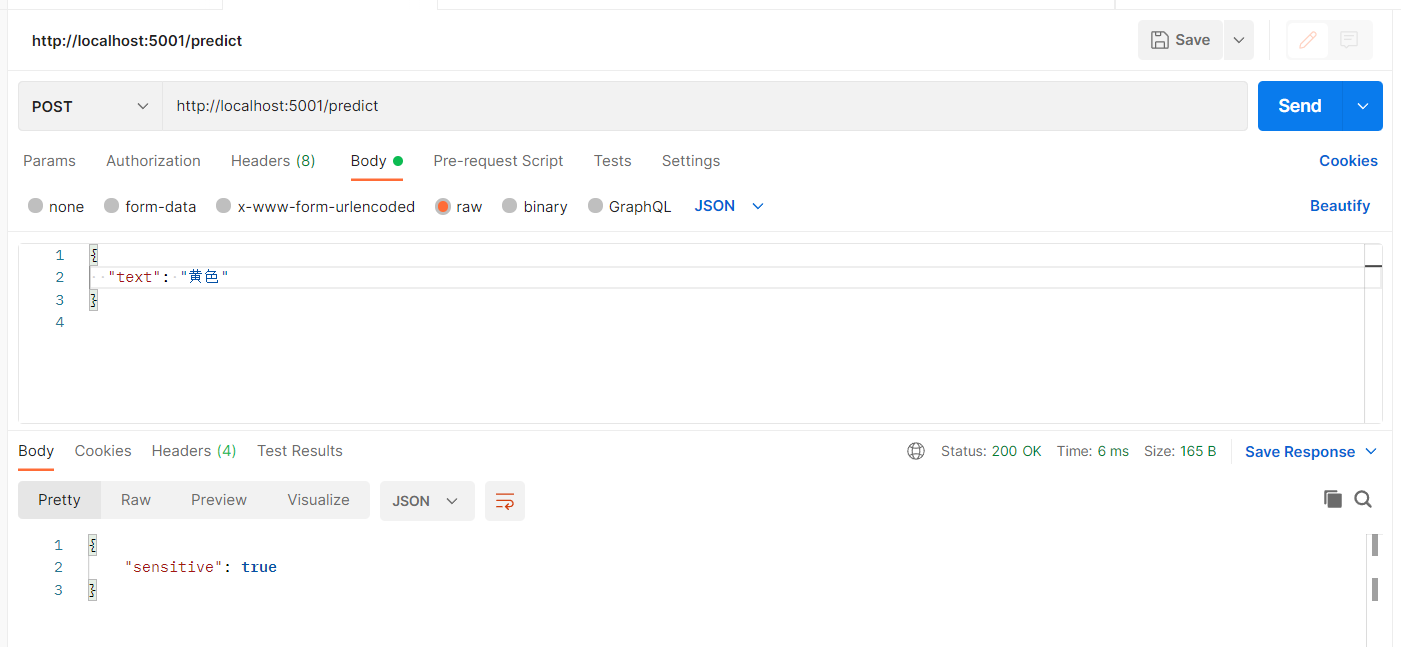
@app.route ( "/predict", methods=["POST"] )
def predict():
data = request.get_json ()
text = data.get ( "text", "" )
X_new = vectorizer.transform ( [text] )
pred = model.predict ( X_new )[0]
return jsonify ( {"sensitive": bool ( pred )} )
if __name__ == "__main__":
app.run ( port=5001 )
|